
Beginning in 2017, AMD’s Zen CPU architecture has revitalised the company’s fortunes in myriad segments. Powering a slew of Epyc and Ryzen processors, the modularity of Zen continues to pay performance dividends.
Debuting with the AM5-based Ryzen 9000 Series chips officially released July 31 this year, Zen 5 is a major evolution because design choices here lay the foundation for the next few generations.
Key advancements include improvements to the instruction, integer, and floating-point pipelines, all backed with more on-chip bandwidth. This is a meatier and more capable processor in every meaningful way.

Not just a higher-clocked Zen 4
The incumbent Zen 4 microarchitecture is no mean performer, mind, but there’s only so much mileage in fine-tuning an existing design, especially if building for future workloads. With Zen 5, AMD’s remit is to architect a more powerful core, thus requiring a foundational rethink.
Zen 5 represents a huge leap forward. It’s going to be a pedestal that we’re going to build upon the next several generations.
Mark Papermaster, AMD Chief Technology Officer
Effective processor designs are all about balance. There’s little point in having a wider, more capable engine if you can’t feed it. To this point, Zen 5’s first major update is with a muscular front-end aimed at making more branch predictions per cycle. This is an important area because efficiency here leads to better execution in the core.
Though the L1 instruction cache and general operational cache remain at similar levels to Zen 4, the new design calls for them to be dual-ported, and you see this with the ‘x2’ on the graphic. There are also dual-decode pathways.
These changes take up transistors but ought to improve the quality of branch prediction. As you add more capability, latency generally goes up, yet AMD reckons it has gone down, though didn’t divulge details as to exactly how this is achieved.

Wider execution
Moving on down, with more cycle predictions on tap, we see arguably the biggest change. Every prior Zen generation was effectively the same for integer execution by having six-wide rename and four ALUs. Now, going wider, laying foundations for future generations, the numbers go up to eight and six, respectively.
You can see why it’s important to feed this extra parallelism through enhanced branch prediction. Widening one area doesn’t work if another remains stunted.
As any CPU engineer knows, a wider design lends itself to higher levels of mispredictions that cause potential stalls in the pipeline. Mitigating this, AMD increases the Zen 4-5 execution window by 40%, now supporting up to 448 operations. In effect, you solve one problem, another rears its head.

More cache where it’s needed
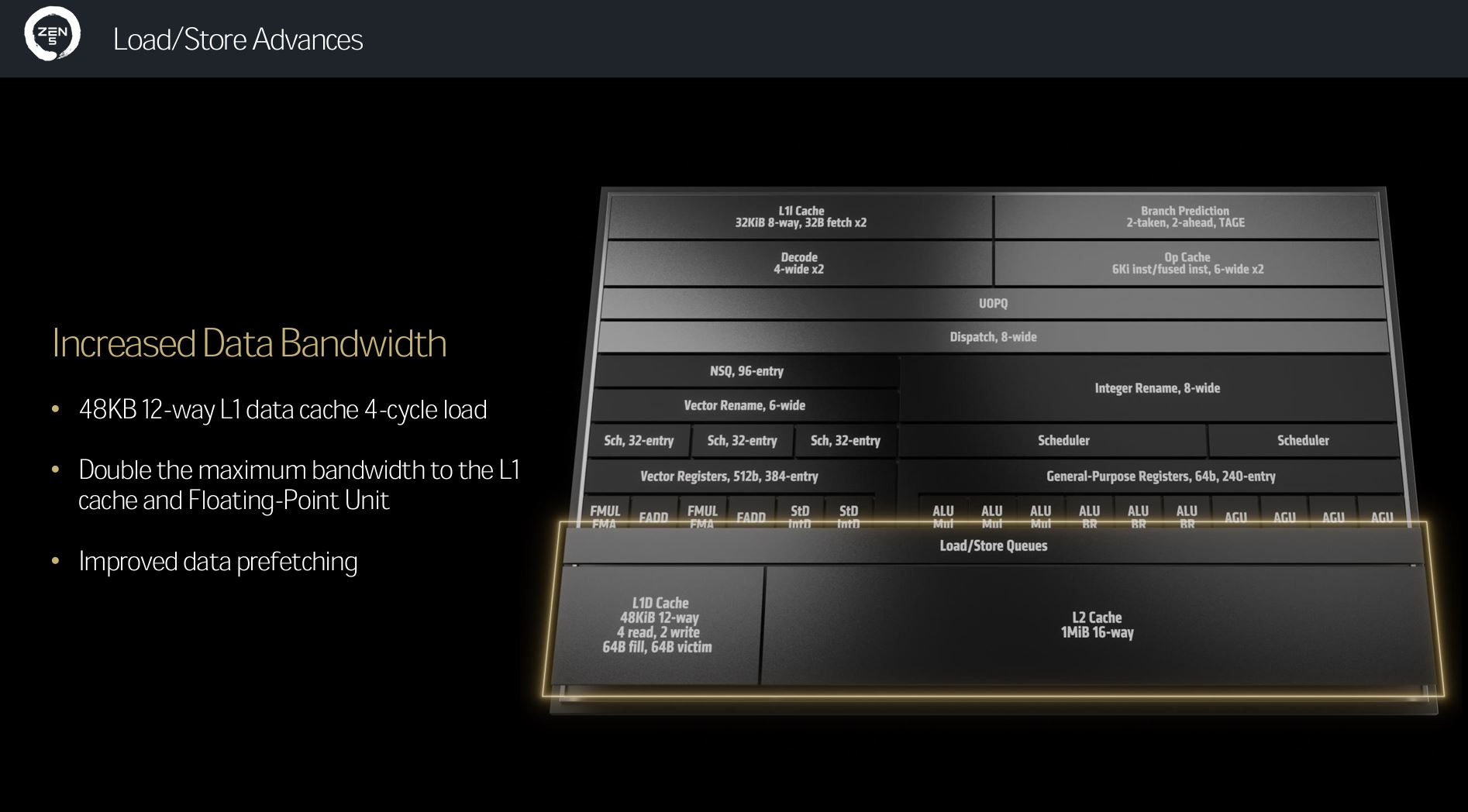
Adding cache where it makes sense the most, Zen 5’s per-core L1 data cache increases by 50%, up from 32KB to 48KB.
The usual trade-off when moving to larger caches is higher access latency – there’s simply more cache to sift through – but AMD says it’s maintained the previous four-cycle access. The cache associativity increases, as well, from 8-way to 12-way.
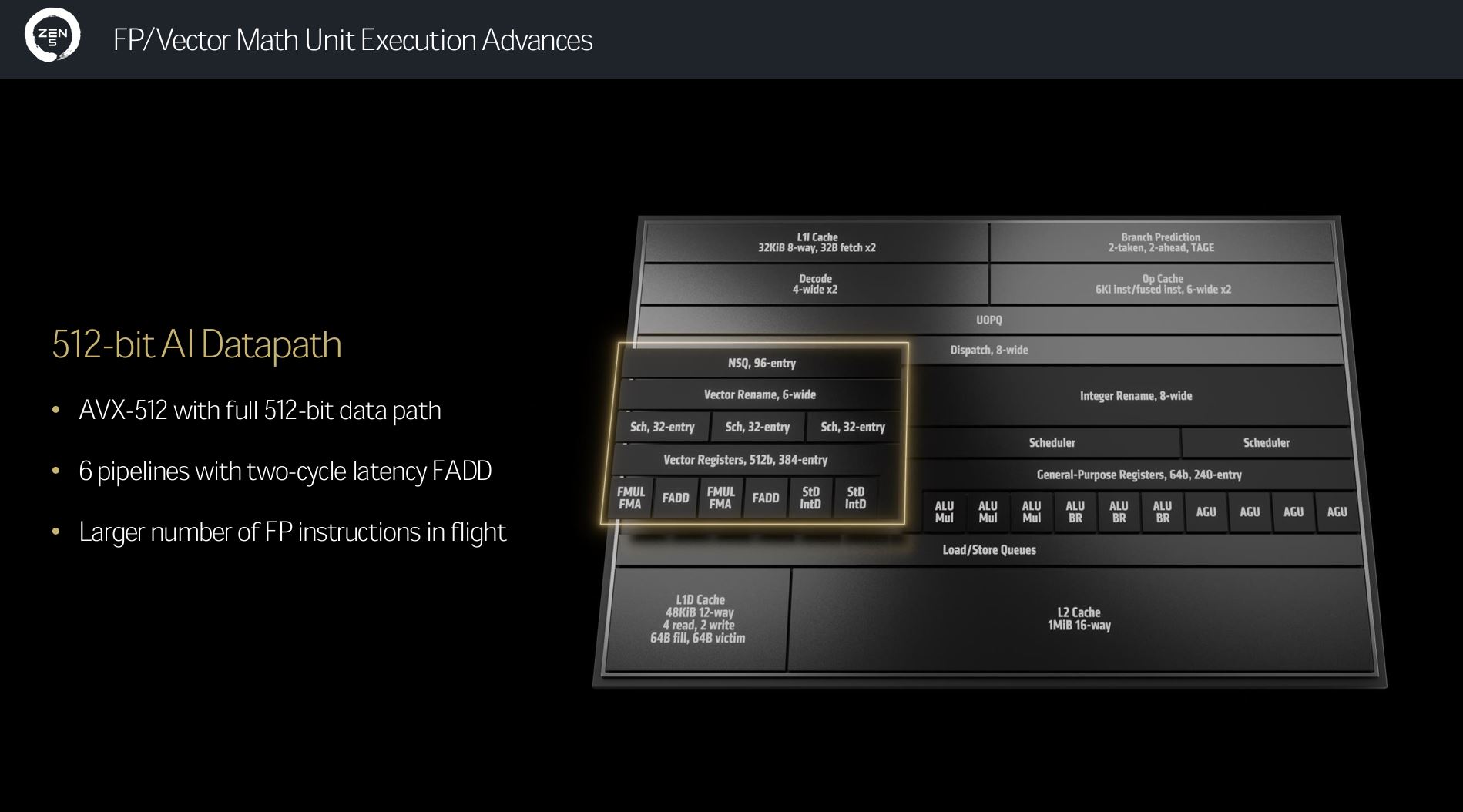
There are a couple further important improvements that pertain to bandwidth, too. Depending upon implementation, Zen 5 is now able to run full AVX-512 in a single cycle thanks to a 512-bit data path, compared with the double-pumping approach (2×256 bits) used on Zen 4. Previously, running a wider path forced a CPU to run at a lower speed; you see this happen on numerous Intel designs.
Zen 5, however, doesn’t diminish frequency, which is another feather in its cap. Should an implementation require double pumping instead of a single pass, ostensibly to save power and die space, AMD can revert back to it, as I suspect will be the case on laptop implementations.
Secondly, zooming in, L2-L1 bandwidth is also doubled between generations, though the former stays at the same 1MB-per-core capacity as Zen 4.
Whichever lever is pulled to increase IPC, there is careful consideration on how it’ll impact associated facets such as die space, frequency, and general throughput. A good idea in isolation may not be a good idea for a complete processor.
Smarter and faster
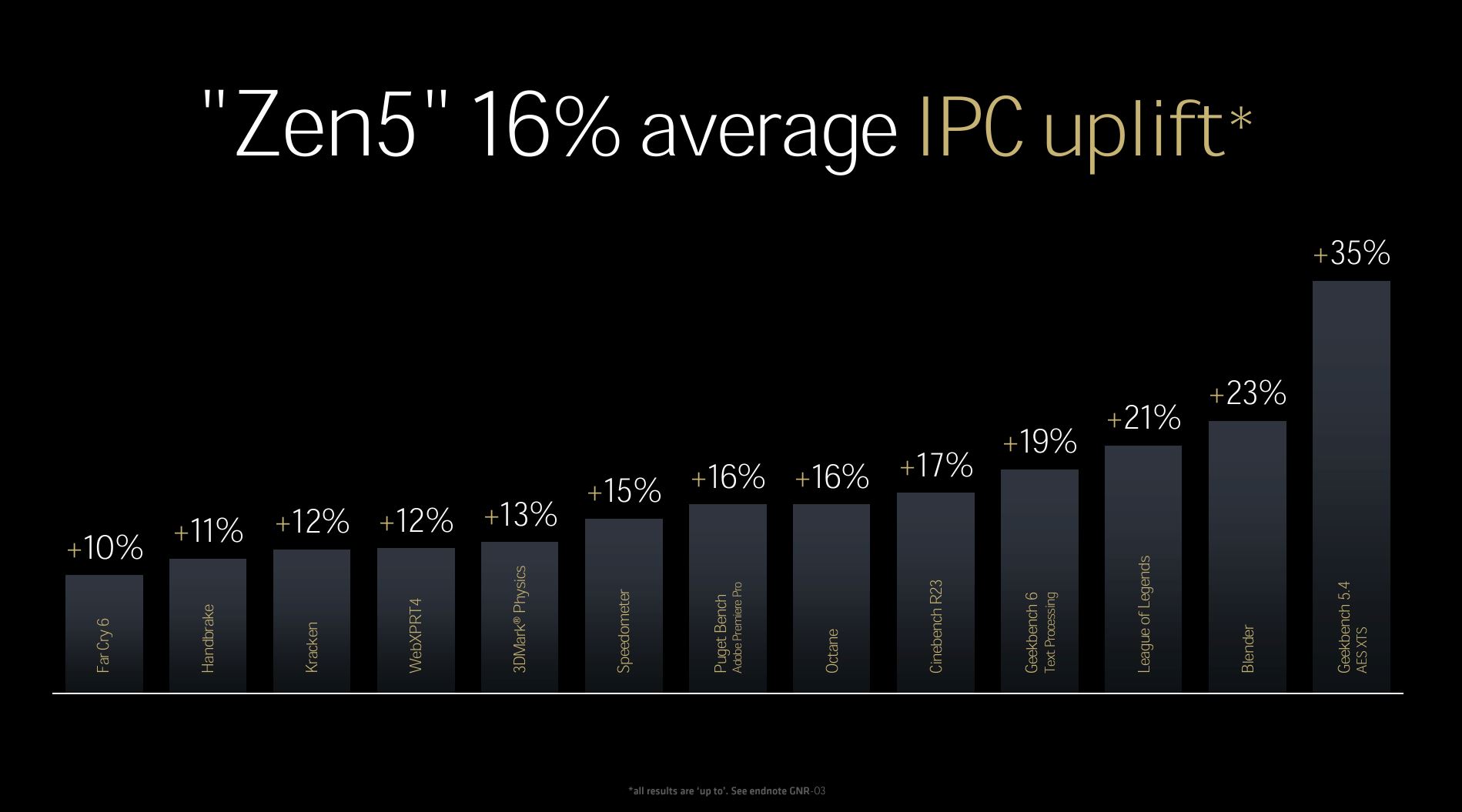
TLDR: the upshot is that Zen 5 has the capability of introducing more instructions to the core, carries an innate facility to execute more of them simultaneously, and also improves the AI-centric floating-point and bandwidth angles that AMD believes will become particularly prevalent and useful in upcoming generations.
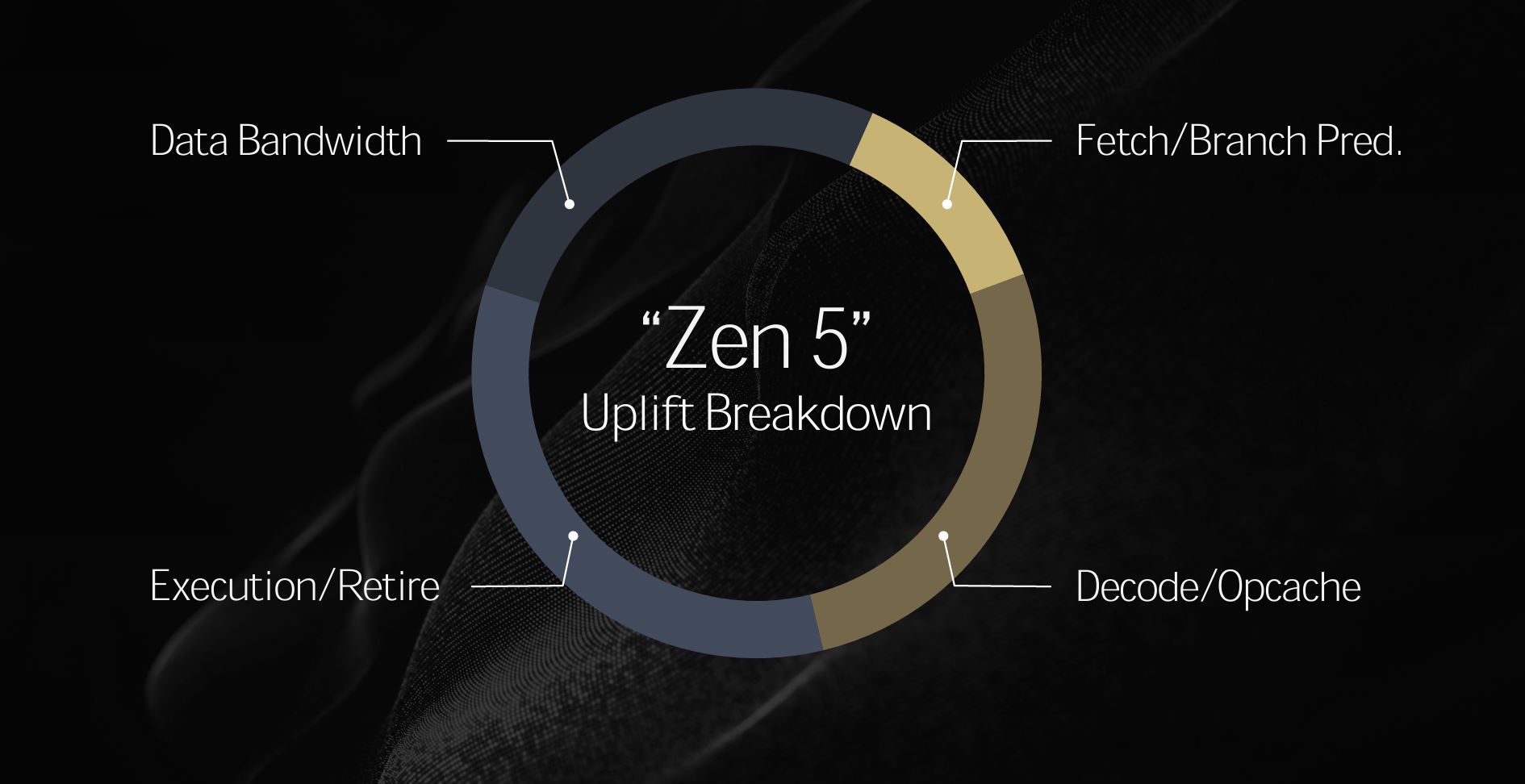
Looking at it holistically, AMD breaks down how each component adds to geomean 16% IPC when compared to Zen 4. Of course, the actual gain depends upon application.
For example, those running math-intensive tasks will see a greater gain, up to 35%, and I expect Zen 5 to pull out a larger iso-frequency IPC lead over Zen 4 as applications veer towards all-consuming AI.
Zen 5 is the heartbeat of the all-new Ryzen 9000 Series desktop chips launching July 31. Head back to the Club on that seminal date for the most in-depth coverage on the web.